
We recently wrote about a new EU law regulating artificial intelligence. This article deals with the expert opinions about the regulation. In particular, they express their concerns about the imperfection of AI.
According to scientists, super-powerful foundation models that adapt to various tasks can make all artificial intelligence systems unsafe, full of prejudice, and opaque. The proposed EU law on artificial intelligence may not be enough to mitigate this threat.
Since the emergence of a super-powerful new type of AI has not been fully accounted for in the proposed EU law, this may mean that the law will quickly become obsolete. It is hard to predict how the technology will be implemented in the future. These can be new and unexpected ways.
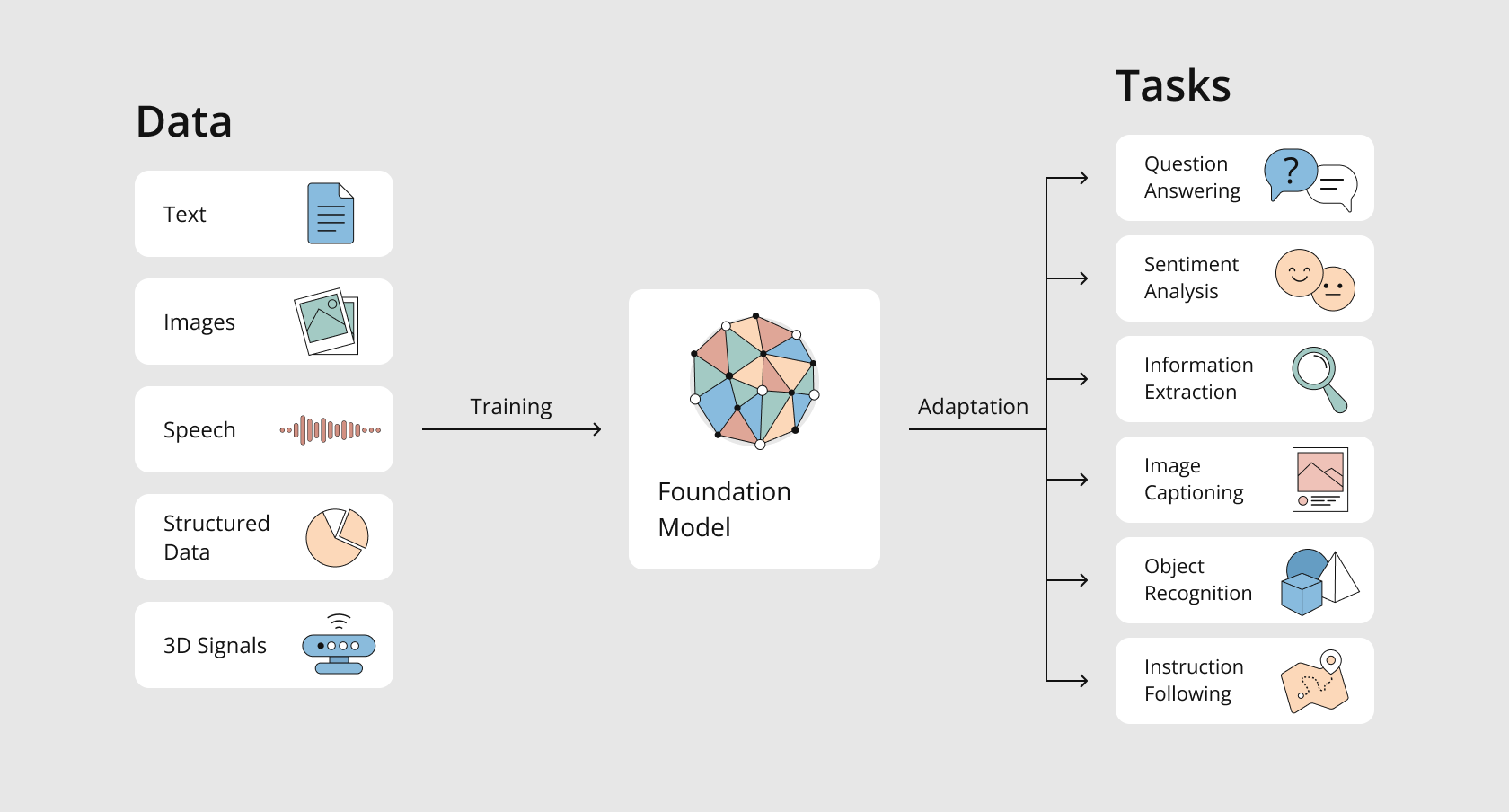
Foundation models are trained on enormous amounts of data by the largest technology companies in the world. Then they will be adapted to a wide range of tasks and will become the infrastructure on which other applications will be built.
Consequently, any shortcomings in the foundation models will be inherited by the applications created on their basis. There is a concern that the underlying models will cause insufficient security and biases in AI.
One study showed that a model trained based on online texts reproduces the prejudices of the Internet, equating Islam with terrorism. This bias can unexpectedly manifest if the model is used, for example, in education.
Thus, if the base is erroneous, the subsequent use will be false.
In August, scientists from Stanford University have reported that there is no clear understanding of how the foundation models work, what will be in the error results, and what they are capable of at all.
Even though some scientists are worried that foundation models will become widespread, some startups have already started to use models to create artificial intelligence tools and services. They include an automatically generated game "Dungeons and Dragons", email assistants, and advertising copy.
Traditional artificial intelligence systems are created for a specific purpose. For example, the diagnosis of X-rays is carried out after data collection, model construction, and deployment. Artificial intelligence can accurately determine whether a patient has pneumonia, spending much less time on it than a specialist.
However, modern applications are isolated, and they cannot be used without human supervision because they do not have common sense knowledge.
Foundation models are trained on a wide range of data, such as online text, images, or videos. They increasingly represent a combination of all three – and therefore, after some tweaking, can be applied to a wide range of different applications.
For example, GTP-3, a model created by the OpenAI Research Laboratory in San Francisco (but now licensed exclusively by Microsoft), is trained on 570 gigabytes of Internet text and can be configured to create, say, chatbots for all kinds of topics.
But the problem with training an artificial intelligence system all over the Internet is that it becomes much more difficult to understand why the foundation model gives a certain conclusion than when the data on which it is trained is precisely defined.
Although AI can generate plausible answers to questions, foundation models do not have any deep understanding of the world. Their conclusions are not based on any truth; they are just based on statistical patterns that sound good together. In one test, the foundation model was deceived by claiming that the apple with the inscription "iPod" on it, is an iPod.
It may be good if an artificial intelligence system can offer creative ideas to the writer, but it is riskier if it is at the heart of a chatbot that should give accurate answers.
Artificial intelligence does not have empathy. It collects a wide variety of data from the Internet, sometimes without any filter. It leads to the fact that chatbots' answers may sound unacceptably rude, touching on issues of gender, race, nationality, religion.
Moreover, since these models extract publicly available data from the Internet, attackers can enter information online, tricking the artificial intelligence system into changing its output data. It is called "data poisoning." It may lead it to think that, for example, the person who is being persecuted is a criminal or a terrorist.
Dig deeper
Critics say that the problem with the EU's proposed AI act is that it regulates or explicitly prohibits the specific use of AI, but does not delve into the foundation models underlying these applications. The act, for example, will ban artificial intelligence applications with "social scoring" or those that "exploit vulnerabilities of a certain group of people."
Instead, a general-purpose AI system will be covered by the act only if the “intended purpose” falls within its scope.
Moreover, it means that the act will shift the burden of regulation from the major technology giants of the United States and China, which own foundation models, to European small and medium-sized enterprises and startups that use models to create artificial intelligence applications.
According to experts, regulation should focus more on the general qualities of the entire artificial intelligence system, for example, whether it is biased or can tell the user that it is not sure of its answer.
If the foundation model has no idea of its own ”knowledge limitations”, it is OK for AI to recommend your next Netflix show. Still, it can be risky if it prescribes medications.
High-risk systems
Lawmakers are likely to keep going back and changing the AI law in the future to ban or regulate new uses of AI subsequently, instead of making sure the underlying models are reliable in the first place. The foundation models should be classified in advance in the law as high-risk systems.
Other artificial intelligence experts also agree that the act needs to be changed to consider the new challenges of the foundation models.
A Commission spokesman confirmed that the AI act’s approach is to scrutinize the “intended use” rather than “the technology as such”. But if an AI system is classified as “high risk”, then “the underlying technology” will be “subject to stringent regulatory scrutiny.”
The list of what counts as “high risk” AI can also be “flexibly updated” if new and unexpected uses of AI “create legitimate concerns about the protection of health, safety, and fundamental human rights,” he said.
This article was rewritten and abridged to be published in our blog. The original article can be found here.
If you find our posts compelling, you can subscribe here. If you have any questions, you may write to info@digt.com: we will be delighted to get feedback.


